Was Reasoning KI Modelle im Unternehmenseinsatz von Standard-LLMs unterscheidet
Seit OpenAIs o1-Modell Ende 2024 das Konzept des „Extended Thinking" einer breiten Nutzerbasis zugänglich machte, hat sich die KI-Landschaft in zwei deutlich unterscheidbare Klassen aufgeteilt: Modelle, die eine Anfrage direkt beantworten, und Modelle, die zunächst intern einen mehrstufigen Denkprozess durchlaufen, bevor sie antworten. Für Entscheider im deutschen Mittelstand ist dieser Unterschied nicht akademisch — er hat direkte Konsequenzen für Budget, Systemarchitektur und Ergebnisqualität.
Reasoning-Modelle — aktuell vertreten durch OpenAIs o3-Familie, Anthropics Claude 3.7 Sonnet mit erweitertem Denkmodus sowie Googles Gemini 2.5 Flash Thinking — generieren vor der sichtbaren Antwort eine interne Gedankenkette. Diese „Chain of Thought" ermöglicht es dem Modell, Widersprüche zu erkennen, Zwischenschritte zu prüfen und Annahmen zu hinterfragen. Das Ergebnis ist eine qualitativ überlegene Ausgabe bei Aufgaben, die echte mehrstufige Schlussfolgerung erfordern.
Das klingt zunächst wie eine rein technische Verbesserung. Für Unternehmen ist es jedoch in erster Linie eine Kostenfrage: Die interne Denkphase verbraucht Token, die in Rechnung gestellt werden. Je nach Modell und Aufgabe kann eine Anfrage an ein Reasoning-Modell das 3- bis 10-fache einer vergleichbaren Standard-Anfrage kosten — und mehrere Sekunden länger dauern. Wer Reasoning-Modelle ohne klares Framework pauschal einsetzt, verbrennt Budget ohne messbaren Mehrwert.
Das Entscheidungsframework: Zwei Achsen, vier Quadranten
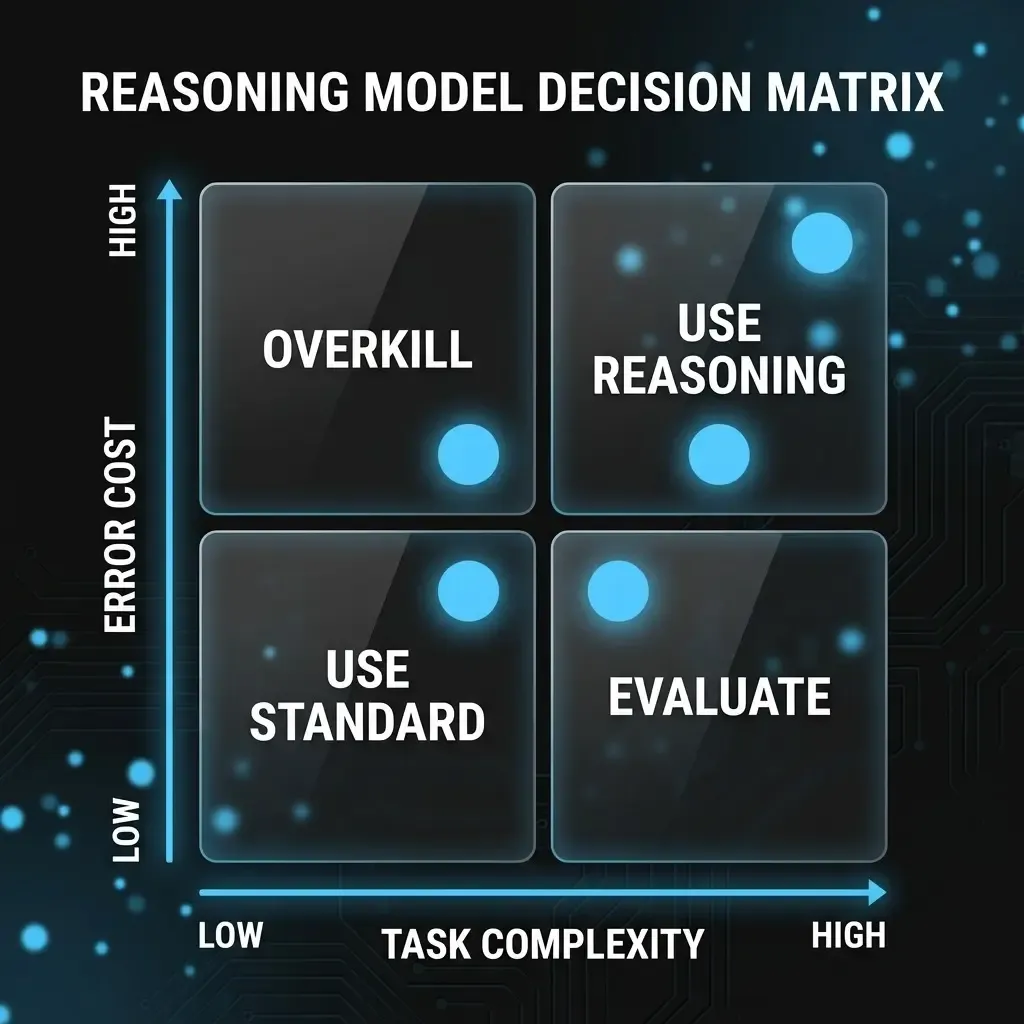
Die nützlichste Methode, den Einsatz von Reasoning-Modellen zu steuern, ist keine Benchmark-Tabelle — es ist eine einfache Zwei-Achsen-Matrix, die jeder Abteilungsleiter oder IT-Verantwortliche selbst anwenden kann. Die erste Achse misst die Aufgabenkomplexität: Erfordert die Aufgabe das Abwägen mehrerer Bedingungen, das Erkennen versteckter Widersprüche oder das Ableiten mehrstufiger Schlussfolgerungen? Die zweite Achse bewertet den Fehlerpreis: Welche Konsequenzen hat eine falsche oder unvollständige Antwort — wird sie von einem Menschen geprüft, oder fließt sie direkt in einen automatisierten Prozess?
Daraus ergeben sich vier Entscheidungsfelder. Aufgaben mit hoher Komplexität und hohem Fehlerpreis — juristische Vertragsanalyse, technische Fehlerdiagnose in sicherheitsrelevanten Systemen, Finanzmodelle zur Investitionsentscheidung — sind genau die Use Cases, für die Reasoning-Modelle entwickelt wurden. Hier rechtfertigt die Qualitätssteigerung den Mehraufwand. Das Gegenteil gilt für Aufgaben mit niedriger Komplexität und niedrigem Fehlerpreis: E-Mail-Zusammenfassungen, Chatbot-Antworten, strukturierte Datentransformation — Standard-Modelle erledigen diese Aufgaben schneller, günstiger und ohne erkennbare Qualitätseinbuße.
Die zwei Graubereiche sind die eigentliche Herausforderung im Alltag. Hohe Komplexität bei niedrigem Fehlerpreis — etwa Brainstorming, Entwurfsgenerierung oder interne Recherche — rechtfertigt Reasoning-Modelle nur dann, wenn ein Mensch das Ergebnis ohnehin noch einmal bewertet. Niedriger Komplexität bei hohem Fehlerpreis ist das häufigste Missverständnis in der Praxis: Wenn ein einfacher, aber kritischer Schritt in einem Automatisierungsworkflow scheitert, liegt das selten an fehlendem Reasoning — sondern an schlechtem Prompt-Design, unvollständigen Kontextdaten oder fehlender Validierungslogik. Mehr Rechenleistung löst diese Probleme nicht.
Konkrete Use Cases: Wo der Unterschied in der Praxis sichtbar wird
In der Praxis beobachten wir bei Unternehmen, die beide Modellklassen einsetzen, ein konsistentes Muster. Reasoning-Modelle liefern messbaren Mehrwert bei: der Analyse von Vertragsklauseln auf Haftungsrisiken, der Ursachendiagnose in komplexen IT-Systemausfällen anhand von Log-Dateien, der Erstellung von Entscheidungsvorlagen für den Vorstand, bei denen mehrere Szenarien gegeneinander abgewogen werden müssen, sowie bei der Prüfung von Compliance-Dokumenten auf regulatorische Widersprüche unter dem EU AI Act oder der DSGVO.
Standard-LLMs behalten ihre Stärken bei allem, was Volumen, Geschwindigkeit und Konsistenz erfordert: automatisierte Kundenkommunikation, die Klassifizierung und Weiterleitung eingehender Dokumente, die Generierung strukturierter Reports aus vordefinierten Datensätzen oder die Zusammenfassung interner Meeting-Protokolle. Der Fehler liegt nicht darin, sich für ein Modell zu entscheiden — sondern darin, keine bewusste Entscheidung zu treffen und pauschal auf das teuerste Modell zu setzen, weil es sich „sicherer anfühlt".

Der hybride Ansatz: Praktische Umsetzung im Mittelstand
Die meisten Unternehmen im deutschen Mittelstand, die KI-Workflows produktiv betreiben, setzen heute auf eine hybride Modell-Architektur: Standard-Modelle für den Volumen-Betrieb, Reasoning-Modelle als selektive Verstärker für definierte Hochwerttasks. Technisch lässt sich das über eine einfache Routing-Logik abbilden — ein vorgelagerter Klassifikator entscheidet anhand von Aufgabentyp und Metadaten, welches Modell aufgerufen wird. Diese Entscheidungslogik muss nicht komplex sein; eine gut dokumentierte Entscheidungstabelle mit 10–15 Aufgabentypen reicht für den Einstieg aus.
Was dabei oft unterschätzt wird: Der größte Hebel für Ergebnisqualität liegt fast immer vor dem Modellaufruf — in der Qualität des Kontexts, der Klarheit der Aufgabendefinition und der Struktur des Prompts. Ein gut vorbereiteter Prompt an ein Standard-Modell schlägt einen schlechten Prompt an ein Reasoning-Modell in fast allen praktischen Szenarien. Reasoning-Modelle maximieren ihren Mehrwert erst dann, wenn Kontext und Aufgabenstellung bereits klar strukturiert sind — und das Modell den Raum bekommt, diese Struktur mehrstufig auszuwerten. Wer heute beginnt, Reasoning-Modelle einzusetzen, sollte deshalb zuerst in Prompt-Architektur investieren — und Modellupgrades als letzten Hebel betrachten, nicht als ersten.