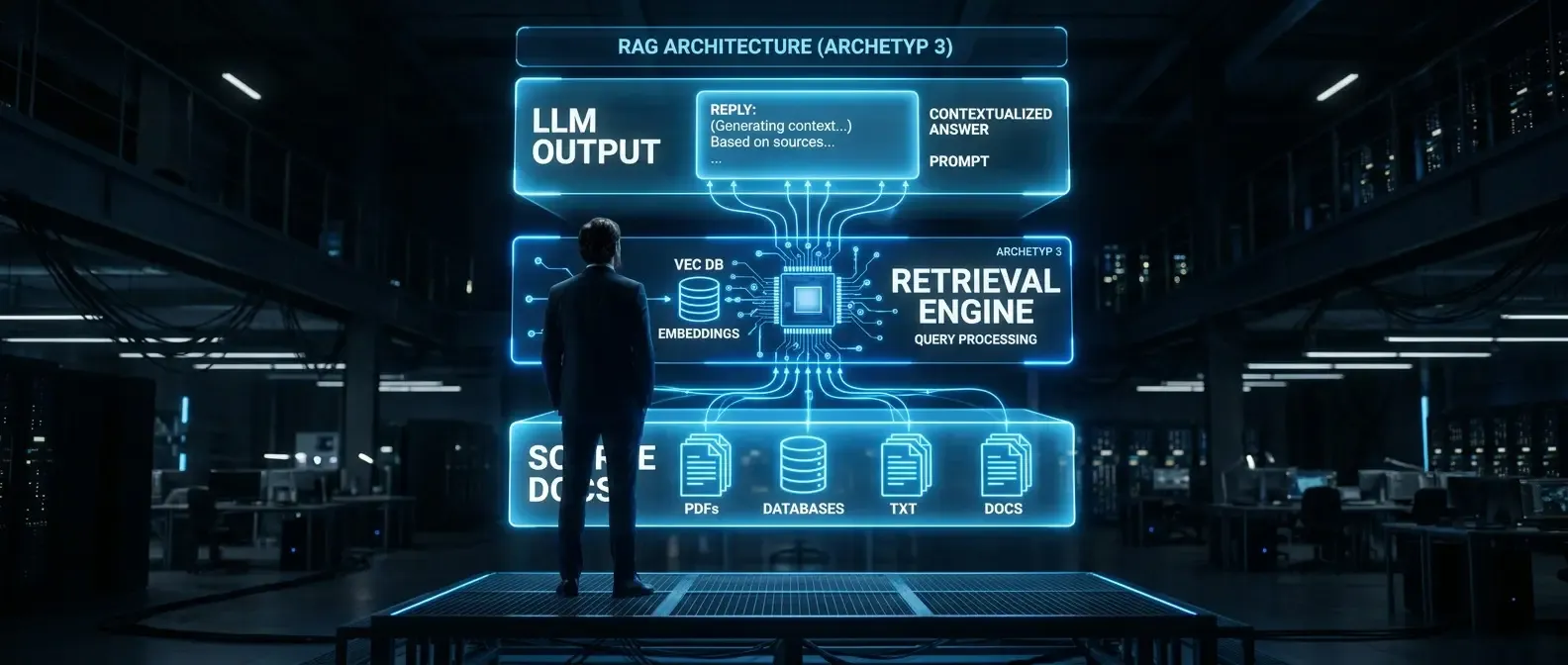
Warum RAG für interne Dokumente so oft unterschätzt wird
Retrieval-Augmented Generation klingt nach einer technischen Entscheidung. In der Praxis ist es zuerst eine organisatorische: Welche Dokumente soll das System kennen? Wer darf auf welche Antworten zugreifen? Wie erkennt das Team, wenn etwas falsch läuft? Diese Fragen werden regelmäßig zu spät gestellt — oft erst dann, wenn das System bereits im Betrieb ist und Nutzer Antworten erhalten, die veraltet, widersprüchlich oder schlicht falsch sind.
RAG für interne Dokumente hat gegenüber allgemeinen LLM-Nutzungsszenarien eine besondere Eigenschaft: Das System spricht im Namen der Organisation. Eine fehlerhafte Antwort zur Urlaubsregelung, zum Einkaufsprozess oder zur Datenschutzrichtlinie ist nicht nur eine schlechte User Experience — sie kann zu Fehlentscheidungen und Compliance-Verstößen führen. Die folgende Checkliste adressiert die zwölf Bereiche, in denen die meisten Implementierungen Lücken aufweisen.
RAG Checkliste: Die 12 kritischen Punkte vor dem Rollout
1. Quellkatalog und Dokumentenperimeter
Definieren Sie exakt, welche Dokumente in den Index aufgenommen werden — und welche nicht. Ein unkontrolliert wachsender Dokumentenpool ist eine der häufigsten Ursachen für schlechte RAG-Qualität. Legen Sie fest: Gilt die aktuelle Fassung oder auch ältere Versionen? Welche Formate werden unterstützt (PDF, DOCX, Confluence, SharePoint)? Wer ist für die Pflege des Quellkatalogs verantwortlich? Der Perimeter muss schriftlich definiert und regelmäßig reviewt werden.
2. Dokumentenqualität und Bereinigung
Schlechte Quellen produzieren schlechte Antworten — ohne Ausnahme. Vor dem Indexieren müssen veraltete, doppelte und widersprüchliche Dokumente bereinigt werden. Das ist kein einmaliger Aufwand, sondern ein laufender Prozess: Ohne Dokumenten-Governance verschlechtert sich die RAG-Qualität mit der Zeit. Einzuplanen sind: ein initialer Bereinigungssprint, ein Versionierungskonzept und ein Update-Prozess für geänderte Inhalte.
3. Zugriffsrechte und Berechtigungslogik
Ein häufig übersehener Punkt: Das LLM weiß nicht, wer welche Dokumente sehen darf. Wenn HR-Richtlinien, Gehaltsstrukturen und Vertragsdokumente im selben Index liegen wie allgemeine Prozesshandbücher, müssen Zugriffsrechte auf Abrufebene erzwungen werden — nicht nur auf Dokumentenspeicherebene. Prüfen Sie, ob Ihr RAG-Framework Row-Level-Security oder dokumentenbasierte Berechtigungsfilter unterstützt, und testen Sie das Verhalten für verschiedene Nutzerrollen explizit.
4. Chunking-Strategie
Wie Dokumente in Chunks aufgeteilt werden, hat direkten Einfluss auf die Retrieval-Qualität. Zu kleine Chunks verlieren Kontext; zu große Chunks reduzieren die Präzision des Abrufs. Es gibt keine universell optimale Chunkgröße — sie hängt von Dokumenttyp, Frageformat und Embedding-Modell ab. Definieren Sie Ihre Chunking-Strategie dokumentiert und reproduzierbar, sodass sie bei Bedarf angepasst und erneut getestet werden kann. Sonderregeln für strukturierte Dokumente (Tabellen, Nummerierungen, Anhänge) müssen separat behandelt werden.
5. Embedding-Modell und Versionierung
Das Embedding-Modell bestimmt, wie semantisch ähnlich Abfrage und Dokument sein müssen, um als Match gewertet zu werden. Ein Wechsel des Embedding-Modells nach dem Indexieren erfordert eine vollständige Neuindexierung — das ist kein trivialer Aufwand. Dokumentieren Sie, welches Modell Sie einsetzen, in welcher Version, und legen Sie fest, unter welchen Bedingungen ein Upgrade evaluiert wird. Stellen Sie sicher, dass Query-Embedding und Dokument-Embedding dasselbe Modell verwenden.
6. Retrieval-Qualität und Testset
Bevor das System in Produktion geht, muss ein repräsentatives Testset mit erwarteten Antworten vorliegen. Das ermöglicht sowohl die initiale Qualitätsmessung als auch Regressionstests bei Änderungen. Mindestanforderung: 30–50 Frage-Antwort-Paare aus echten oder realistischen Nutzungsszenarien, bewertet durch Fachexperten. Metriken wie Recall@k (wie oft enthält die Trefferliste das relevante Dokument?) und MRR (Mean Reciprocal Rank) geben objektive Vergleichswerte.
7. Halluzinationsrisiko und Quellenangaben
Auch ein gut konfiguriertes RAG-System kann halluzinieren — insbesondere wenn die Retrieval-Ergebnisse keine passende Antwort enthalten, das LLM aber dennoch antwortet. Definieren Sie ein explizites Verhalten für den Fall, dass keine relevanten Quellen gefunden werden: Das System sollte transparent signalisieren, dass es keine gesicherte Antwort geben kann, statt zu improvisieren. Quellenangaben in der Antwort (Dokumentname, Version, Absatz) sind kein Nice-to-have, sondern eine Grundvoraussetzung für Nachvollziehbarkeit und Vertrauen.
8. DSGVO-Konformität und Datenspeicherung
Werden Anfragen und Antworten gespeichert? Wo liegen die Vektordatenbank und das LLM — On-Premise, EU-Cloud oder US-Anbieter? Welche personenbezogenen Daten könnten in den Dokumenten enthalten sein, und wie wird verhindert, dass diese unkontrolliert abgerufen werden? Diese Fragen müssen vor dem Go-live mit Datenschutzbeauftragten und Legal abgestimmt sein. Eine nachträgliche DSGVO-Korrektur an einem bereits laufenden System ist aufwändig und teuer.
9. Nutzergruppen und Rollenkonzept
Wer nutzt das System für welche Zwecke? Ein einheitlicher Zugang für alle Mitarbeitenden ist selten sinnvoll. Definieren Sie Nutzergruppen mit unterschiedlichen Dokumentenzugängen, Prompting-Vorlagen und ggf. separaten Indizes. Ein Vertriebsmitarbeiter braucht andere Kontexte als ein Buchhalter oder ein Projektleiter. Die Rollensegmentierung beeinflusst sowohl die Berechtigungslogik als auch die Qualität der Retrieval-Ergebnisse.
10. Prompt-Engineering und System-Instruktionen
Der System-Prompt ist der unsichtbare Rahmen jeder Antwort. Er definiert Ton, Grenzen und Verhalten des Assistenten. Legen Sie fest: Welche Sprache und welchen Tonfall soll das System verwenden? Was darf es nicht beantworten — und wie kommuniziert es das? Wie soll mit mehrdeutigen Anfragen umgegangen werden? System-Prompts sollten versioniert und durch Fachbereiche freigegeben werden, bevor sie in Produktion gehen. Eine unkontrollierte Änderung kann Verhalten grundlegend verändern, ohne dass es sofort auffällt.
11. Monitoring, Logging und Feedback-Loop
Ein RAG-System, das keine Nutzungsdaten sammelt, kann nicht systematisch verbessert werden. Definieren Sie vor dem Go-live: Welche Metriken werden täglich überwacht (Anfragevolumen, durchschnittliche Retrieval-Trefferquote, Nutzerfeedback-Score)? Wie können Nutzer schlechte Antworten melden, und wer wertet diese Meldungen aus? Wann wird ein Dokument aus dem Index entfernt, weil es zu Fehlantworten führt? Ohne diesen Feedback-Loop degradiert die Qualität über Zeit, ohne dass es aktiv auffällt.
12. Kommunikation und Change Management
Auch das beste RAG-System scheitert, wenn Nutzer nicht wissen, wofür es gedacht ist und wo seine Grenzen liegen. Kommunizieren Sie klar: Was kann das System — und was nicht? Wann sollte ich eine Anfrage lieber direkt an einen Kollegen stellen? Dass Antworten auf interne Dokumenten basieren, aber trotzdem geprüft werden sollten. Onboarding-Materialien, ein FAQ und ein klarer Eskalationspfad für kritische Anfragen sind keine Extras — sie sind Teil der Implementierung.
Die zwölf Punkte dieser RAG interne Dokumente Checkliste sind kein einmaliges Gate vor dem Go-live. Sie sind die Grundlage eines laufenden Betriebs. Organisationen, die diese Punkte vor dem Rollout klären, vermeiden nicht nur technische Probleme — sie schaffen die Voraussetzungen dafür, dass Mitarbeitende dem System vertrauen und es tatsächlich nutzen. Und das ist das eigentliche Ziel.