What sets reasoning models apart from standard LLMs
Since OpenAI’s o1 family made “extended thinking” visible to a wide audience, the landscape has split into two classes: models that answer in one shot, and models that run an internal multi-step reasoning pass before responding. For leaders, that is not academic — it directly affects budget, architecture, and output quality.
Reasoning models — including OpenAI’s o3 family, Anthropic’s Claude 3.7 Sonnet with extended thinking, and Google’s Gemini 2.5 Flash Thinking — build an internal chain of thought before the user-visible answer. That helps resolve contradictions, check intermediate steps, and stress-test assumptions. The trade-off is cost: the internal phase burns billable tokens and adds seconds of latency.
For enterprises this is primarily a commercial question. Without a clear framework, blanket use of reasoning models burns budget without measurable uplift.
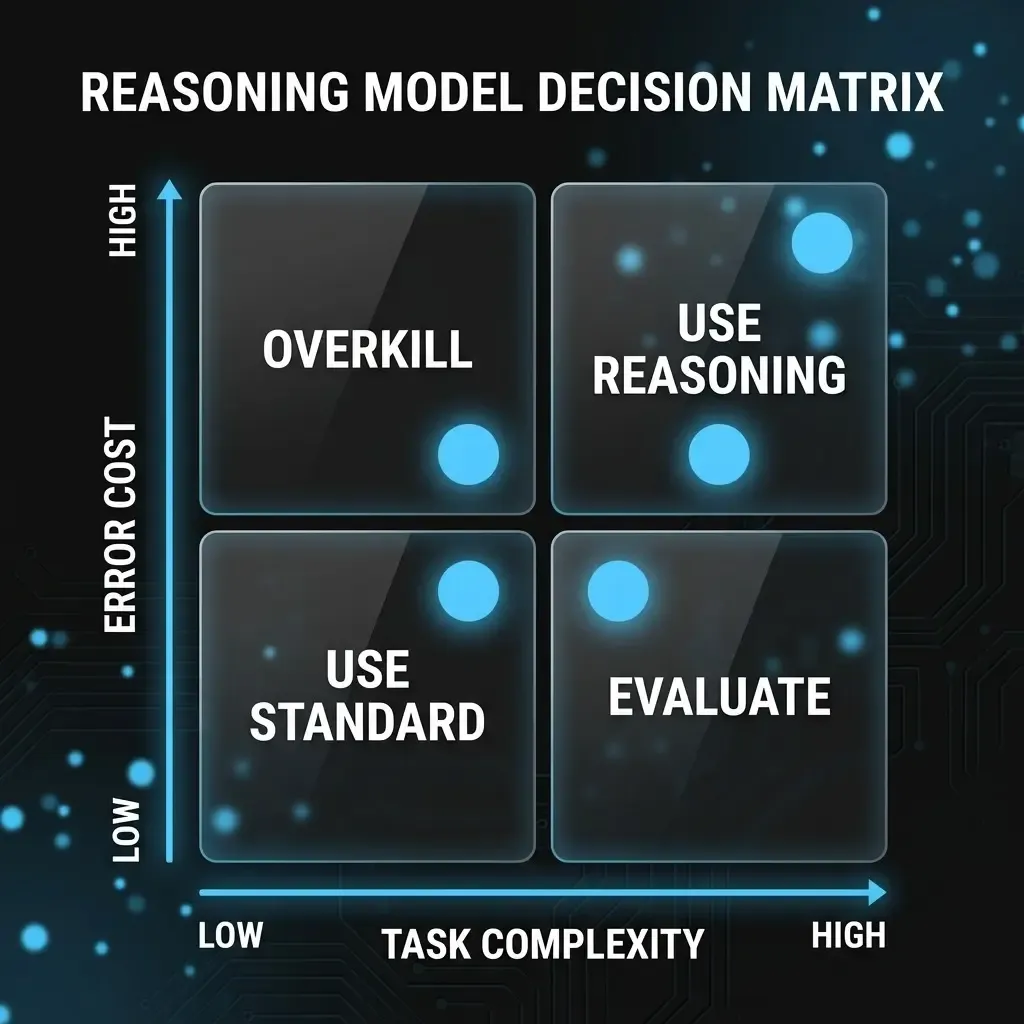
A simple framework: two axes, four quadrants
The most useful steering tool is not a benchmark table — it is a two-axis matrix any line manager can apply. Axis one is task complexity: does the task need weighing multiple constraints, spotting hidden contradictions, or multi-step inference? Axis two is cost of error: what happens if the answer is wrong or incomplete — human review, or straight into automation?
High complexity and high cost of error — contract liability review, safety-critical diagnostics, investment models — are where reasoning models earn their keep. Low complexity and low cost of error — email summaries, chatbots, light data transforms — stay with standard models: faster, cheaper, and good enough.
The grey zones matter most. High complexity, low cost of error (brainstorming, drafts) justifies reasoning only if a human still judges the output. Low complexity, high cost of error is often misunderstood: failure here is rarely “not enough reasoning” — it is weak prompts, thin context, or missing validation logic. More compute does not fix that.
Where the gap shows up in practice
Teams that run both classes consistently see the same pattern. Reasoning models add measurable value for clause-level contract risk review, root-cause analysis from messy logs, board-ready decision memos that weigh scenarios, and compliance checks for tension between GDPR and the EU AI Act.
Standard LLMs keep their edge wherever volume, speed, and consistency dominate: customer messaging, document triage, structured reporting from known datasets, and internal meeting summaries. The mistake is not choosing one class — it is not choosing at all and defaulting to the most expensive model because it “feels safer”.

Hybrid deployment in the mid-market
Most organisations running AI in production use a hybrid architecture: standard models for volume, reasoning models as a selective boost for defined high-value tasks. A lightweight router — even a documented decision table with 10–15 task types — is enough to start.
The biggest quality lever usually sits before the model call: context quality, task definition, and prompt structure. A well-prepared prompt to a standard model beats a poor prompt to a reasoning model in most real settings. Invest in prompt architecture first; treat model upgrades as a later lever, not the first.