
Why this decision so often stalls
Many enterprises have evaluated the internal LLM, built the business case — and then come to a standstill. The most common cause is not lack of will but an unanswered fundamental question: will the model be operated in-house or sourced via a cloud provider? IT, data protection, procurement, and business units often have conflicting requirements that have never been brought together in a single meeting.
The problem: this decision is frequently treated as a technical detail for the IT department to resolve later. In practice it is a strategic fork in the road — it determines how much operational overhead is incurred on an ongoing basis, who has access to model inputs, and how flexible the system will be as usage grows. Making it too late means building pilots on assumptions that don't hold in production.
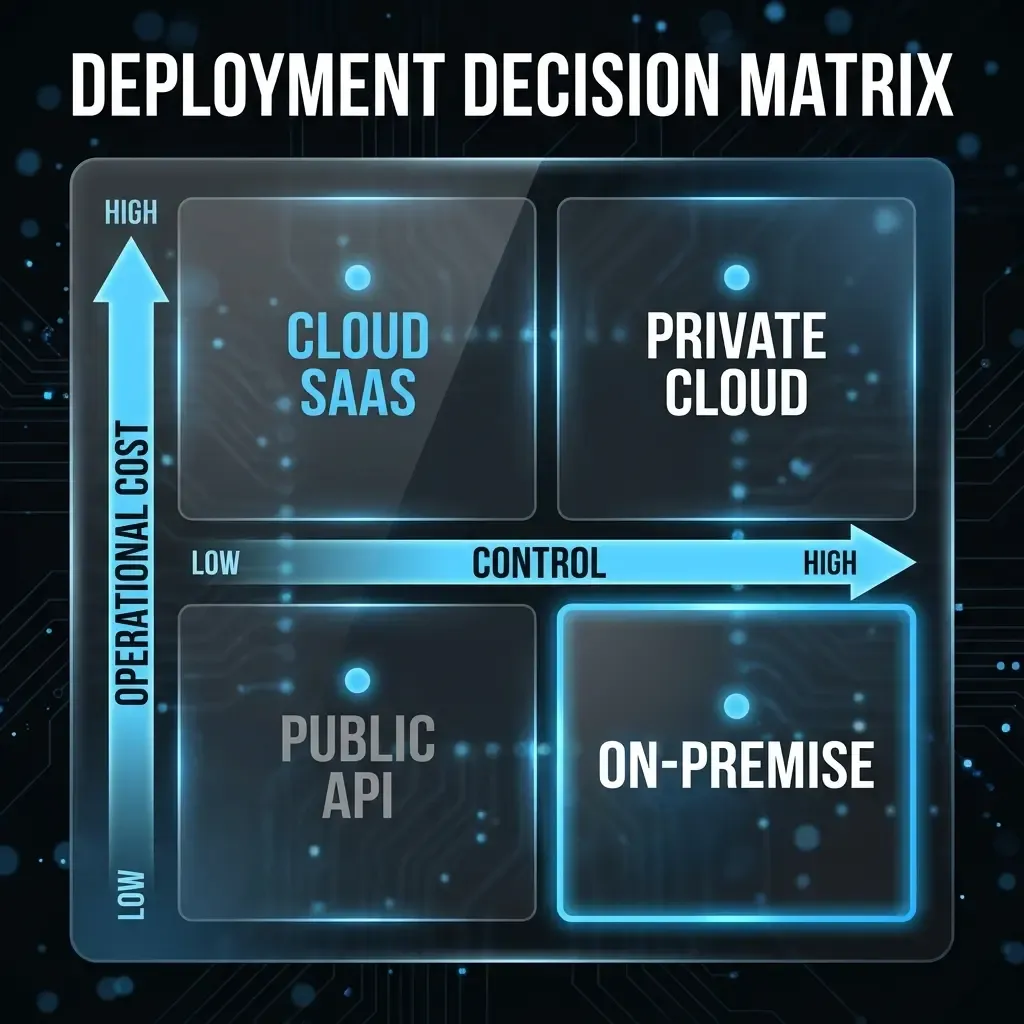
LLM on-premise vs. cloud compared: the six decision dimensions
A defensible decision for on-premise or cloud cannot be derived from a single requirement. Six dimensions must be assessed together — with concrete implications depending on the organisational context.
1. Data protection & GDPR: Cloud does not automatically mean GDPR non-compliance — what matters is the data category, the location of processing, and the data processing agreement in place. Organisations that process personal data or embed confidential business documents in prompts must verify that the model vendor does not use this data for training. Most enterprise offerings exclude this contractually. On-premise provides maximum control but shifts full responsibility to the organisation.
2. TCO & cost: Cloud models appear cheaper in pilot phases because infrastructure is absent. At higher volumes the picture reverses: pay-per-token pricing scales linearly, while GPU servers amortise beyond a certain usage threshold. On-premise ties up capital and generates fixed operating costs — even when the model is idle overnight. A 3-year TCO model should always be calculated before a direction is fixed.
3. Latency & performance: Local inference is generally faster than API calls over the internet — especially when high concurrency is required. For internal knowledge assistants with spread usage patterns the difference is often marginal. For real-time applications (live transcription, customer interactions requiring sub-second response) latency becomes a genuine differentiator.
4. Model control & customisability: On-premise enables full fine-tuning on proprietary data, custom system configurations, and independent model versioning. Cloud APIs typically offer only prompt engineering and limited fine-tuning options. Organisations that require a highly specialised model for specific business terminology or regulated outputs gain significantly more flexibility through self-hosted operation.
5. Maintenance & operations: Self-operated models require ongoing care: security patches, model updates, hardware monitoring, incident response. This represents real operational overhead that must be carried by a qualified team — not just at launch, but permanently. For organisations without a dedicated ML-Ops team this is often the underestimated cost driver. Cloud offloads these responsibilities to the provider.
6. Scalability & flexibility: Cloud infrastructure scales elastically — more users mean more API calls, no capacity bottleneck. On-premise requires forward-looking hardware planning: too little compute creates queuing delays, too much ties up capital. For organisations with unpredictable usage growth, cloud has a clear advantage here.
When on-premise is genuinely the right choice
On-premise is the right choice when at least two of the following conditions apply: the organisation processes highly sensitive data for which cloud processing is not acceptable. There is an existing IT team experienced in GPU operations, or the willingness to build one. Usage volume is high and predictable enough to amortise the hardware investment. Significant model customisation (fine-tuning, proprietary versioning) is planned.
Organisations in regulated industries — pharma, finance, insurance — often have legitimate reasons for on-premise. The mistake lies in using data protection as the only argument without honestly calculating operating costs.
When cloud is the better choice
Cloud suits organisations that want to move fast, have no ML-Ops capacity, and whose data profile allows cloud processing under an appropriate data processing agreement. For proof-of-concept phases cloud is clearly preferable: no capex risk, immediate availability, easy model switching. Many enterprises start with cloud and only migrate once usage volume justifies the break-even point for own hardware.

Hybrid architectures as a practical middle ground
The majority of organisations we work with end up not with a clean either-or but with a hybrid architecture: general workloads — internal FAQ systems, document summaries without confidential content — run via cloud APIs. Sensitive processes — legal review with contract data, HR queries with personnel records — are handled on own compute or via private cloud instances (e.g. Azure Government, dedicated tenant isolation).
The decisive first step is data classification: which information flows into which LLM workflows? From this, it becomes almost automatic to see where cloud is acceptable and where self-hosted operation is mandatory. Without that classification, any deployment discussion remains speculative.