
The untapped knowledge capital of the enterprise
A mid-sized company with 200 employees produces thousands of documents every year: operating manuals, contract templates, compliance policies, onboarding materials, proposal frameworks, support logs. Everything lands somewhere — in SharePoint folders, network drives, email archives, or in the heads of colleagues who have long since left the organisation.
The result is always the same: employees spend 20–30 % of their working time searching for information that already exists. New colleagues ask the same questions repeatedly. Expert knowledge concentrates in a handful of people and becomes a bottleneck. A RAG system solves this problem structurally — not by requiring more data maintenance, but by intelligently connecting what already exists.
RAG system for enterprise: how the core principle works
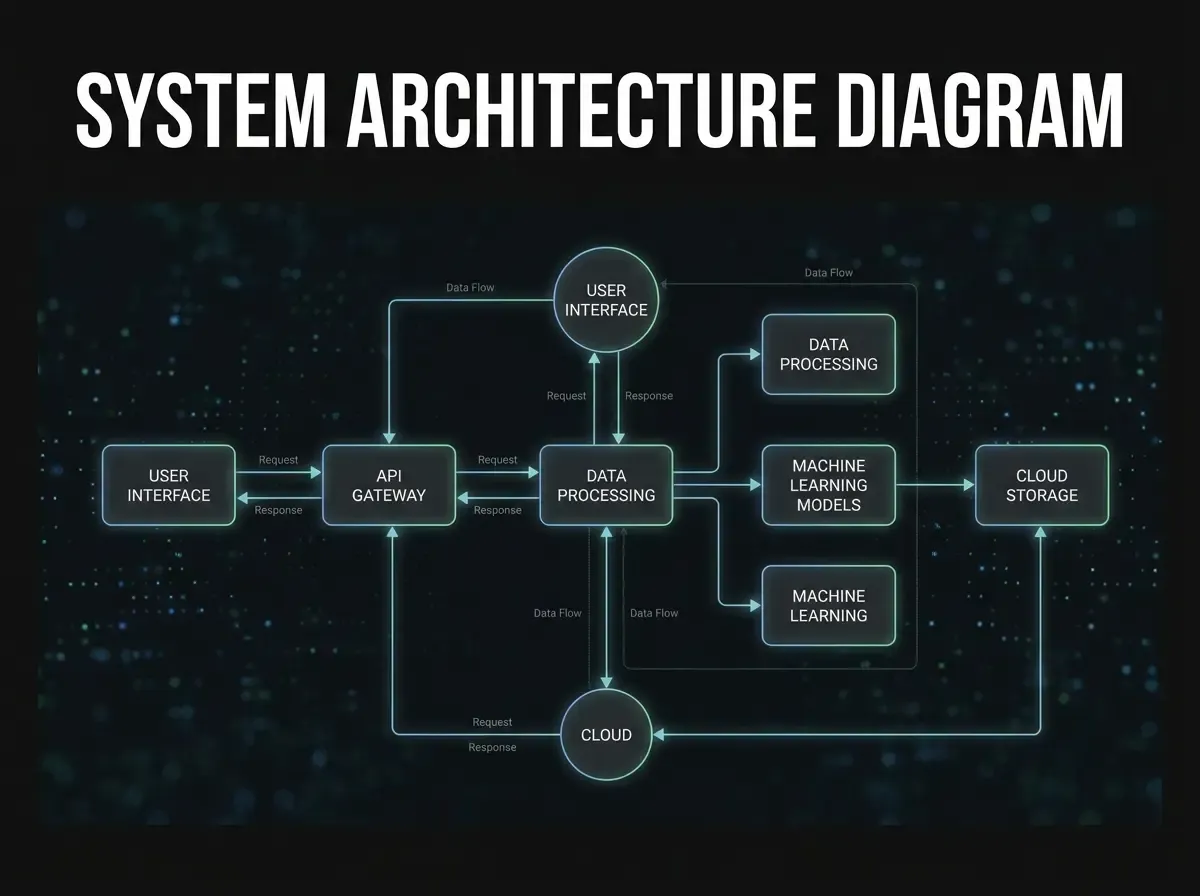
RAG stands for Retrieval-Augmented Generation. The principle is simpler than it sounds. A RAG system consists of two components: a retrieval mechanism and a language model. When an employee asks a question, the system first searches the indexed documents for relevant text passages — and passes these as context to the language model, which then formulates a precise, source-based answer.
The critical difference from a standard chatbot: the language model does not invent answers from its training knowledge. It reads the relevant passages from your own documents and synthesises them. This drastically reduces hallucinations and makes every answer verifiable — with a direct reference to the source document.
The technical process in four steps: (1) Documents are divided into small semantic sections (chunks) and indexed as vectors. (2) An incoming question is also vectorised and compared to the index. (3) The semantically closest passages are retrieved. (4) The language model generates an answer based on those passages. No fine-tuning, no retraining — the model itself remains unchanged.
This architecture has another strategic advantage: the organisation remains model-independent. Whether GPT-4o, Claude, Mistral or a self-hosted open-source model such as Llama — the RAG layer works with any language model. This avoids vendor lock-in and allows incremental transitions when newer models become better or cheaper.
The four phases of a RAG implementation
A RAG project is not a classic IT project with months of specification. In practice it can be broken into four manageable phases, completed sequentially in 4–8 weeks.
Phase 1 — Document inventory & quality review: Which documents exist, where are they stored, and which are current and reliable enough to serve as a knowledge source? Poor source document quality is the most common reason for disappointing RAG results. Outdated, contradictory or poorly structured PDFs produce incorrect answers — even with a technically flawless system configuration.
Phase 2 — Chunking, embedding & indexing: Cleaned documents are divided into semantic sections (typically 300–800 tokens) and stored as vectors in a vector database. This is where answer accuracy and retrieval speed are determined. Chunk size, overlap strategy and the embedding model are the most important levers.
Phase 3 — Pilot & evaluation: A controlled pilot with a defined user group (e.g. customer service or HR) provides real quality data. Gold-standard questions with known answers allow objective measurement of precision. Only once precision and recall are consistently above a defined threshold is the next phase initiated.
Phase 4 — Rollout, access control & operations: Not every employee should have access to all documents. Personnel files, salary structures, strategic planning documents — a production-ready RAG system must inherit and enforce access rights from the existing IAM system (Active Directory, Entra ID). Documents a user has no read permission for must neither be retrieved nor passed as context to the language model.
GDPR compliance: what really matters with a RAG system
The GDPR question for a RAG system is different from a direct API deployment of ChatGPT or Copilot. In the RAG scenario your source documents do not leave the organisation — they are indexed and stored locally. Only the user's query and the retrieved passages are passed to the language model. If that model runs on-premises or in a certified EU data centre, the data protection requirements are minimal.
The more critical question is which personal data is embedded in the source documents. Email archives, customer correspondence and HR records should be either pseudonymised, access-restricted, or excluded from the RAG index entirely. A careful document classification in Phase 1 is therefore not just a technical chore — it is the data protection foundation of the entire system.
Organisations self-hosting an open-source model such as Llama or Mistral retain full data sovereignty. Those using a cloud provider should verify: processing exclusively within the EU, a signed data processing agreement (DPA), and deactivation of model training on customer data. Providers such as Microsoft Azure OpenAI, AWS Bedrock and Google Vertex AI offer these options explicitly — but only when actively configured.