
Das ungenutzte Wissenskapital des Mittelstands
Ein mittelgroßes Unternehmen mit 200 Mitarbeitern produziert jedes Jahr Tausende von Dokumenten: Betriebshandbücher, Vertragsvorlagen, Compliance-Richtlinien, Einarbeitungsunterlagen, Angebotsvorlagen, Support-Protokolle. Alles landet irgendwo — in SharePoint-Ordnern, Laufwerken, E-Mail-Archiven oder im Hirn von Kollegen, die das Unternehmen längst verlassen haben.
Das Ergebnis ist immer dasselbe: Mitarbeiter suchen 20–30 % ihrer Arbeitszeit nach Informationen, die eigentlich vorhanden sind. Neue Kollegen stellen dieselben Fragen immer wieder. Expertenwissen konzentriert sich auf wenige Personen und wird zum Engpass. Ein RAG-System löst dieses Problem strukturell — nicht durch neue Datenpflege, sondern durch intelligente Verknüpfung dessen, was bereits existiert.
RAG-System Mittelstand: So funktioniert das Grundprinzip
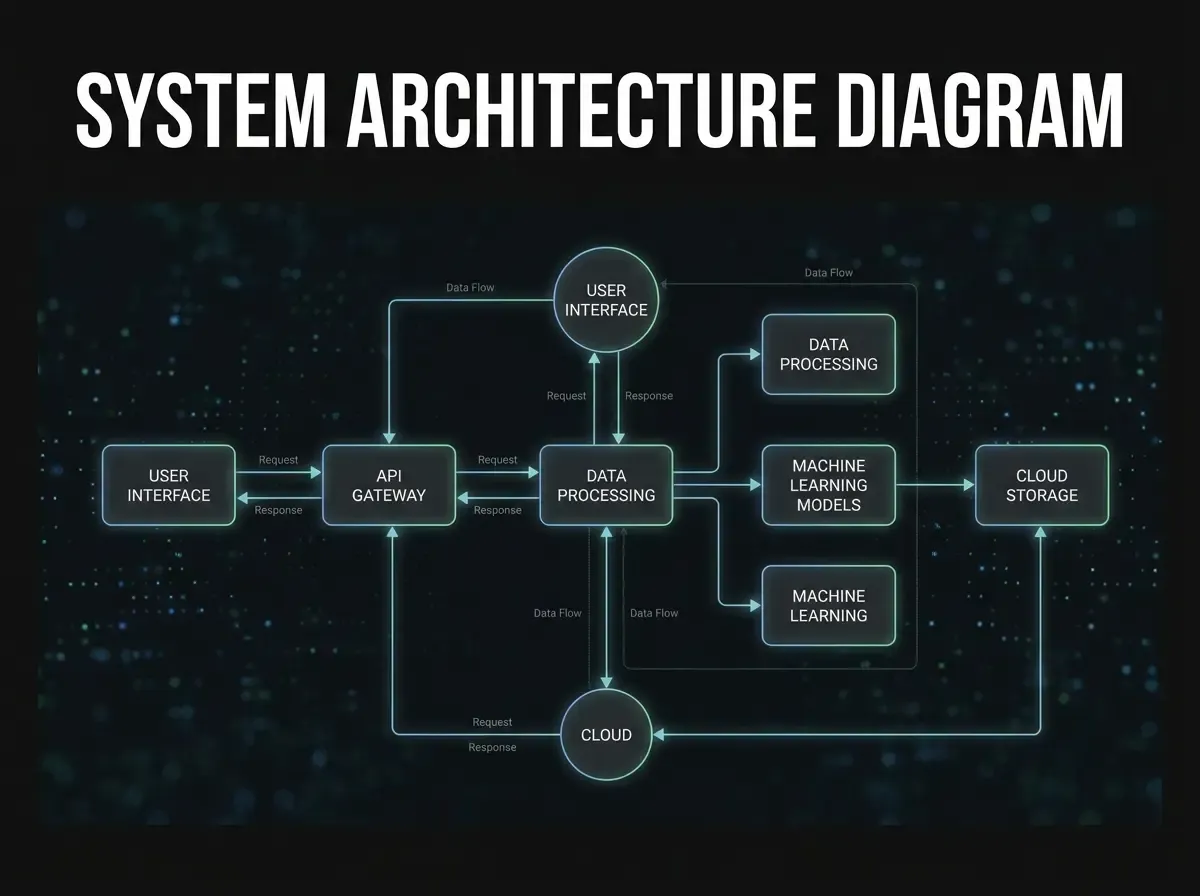
RAG steht für Retrieval-Augmented Generation — auf Deutsch: abrufgestützte Textgenerierung. Das Prinzip ist einfacher als es klingt. Ein RAG-System besteht aus zwei Komponenten: einem Abrufmechanismus (Retrieval) und einem Sprachmodell (Generation). Wenn ein Mitarbeiter eine Frage stellt, sucht das System zuerst in den hinterlegten Dokumenten nach relevanten Textpassagen — und übergibt diese als Kontext an das Sprachmodell, das dann eine präzise, quellenbasierte Antwort formuliert.
Der entscheidende Unterschied zu einem normalen Chatbot: Das Sprachmodell erfindet keine Antworten aus seinem Trainingswissen. Es liest die relevanten Passagen aus Ihren eigenen Dokumenten und synthetisiert sie. Das reduziert Halluzinationen drastisch und macht jede Antwort verifizierbar — mit direktem Verweis auf die Quelldokumente.
Der technische Ablauf in vier Schritten: (1) Dokumente werden in kleine semantische Abschnitte (Chunks) unterteilt und als Vektoren indiziert. (2) Bei einer Anfrage wird die Frage ebenfalls vektorisiert und mit dem Index verglichen. (3) Die semantisch ähnlichsten Passagen werden abgerufen. (4) Das Sprachmodell generiert auf Basis dieser Passagen eine Antwort. Kein Fine-Tuning, kein Nachtraining — das Modell selbst bleibt unverändert.
Diese Architektur hat einen weiteren strategischen Vorteil: Das Unternehmen bleibt modellunabhängig. Ob GPT-4o, Claude, Mistral oder ein selbst gehostetes Open-Source-Modell wie Llama — der RAG-Layer funktioniert mit jedem Sprachmodell. Das vermeidet Vendor-Lock-in und erlaubt schrittweise Umstellungen, wenn neue Modelle besser oder günstiger werden.
Die vier Phasen einer RAG-Implementierung im Unternehmen
Ein RAG-Projekt ist kein klassisches IT-Projekt mit monatelanger Spezifikation. Erfahrungsgemäß lässt es sich in vier überschaubare Phasen unterteilen, die sequenziell in 4–8 Wochen durchlaufen werden können.
Phase 1 — Dokumenten-Inventory & Qualitätsprüfung: Welche Dokumente existieren, wo liegen sie, welche sind aktuell und zuverlässig genug, um als Wissensquelle zu dienen? Eine schlechte Quelldokument-Qualität ist der häufigste Grund für enttäuschende RAG-Ergebnisse. Veraltete, widersprüchliche oder schlecht strukturierte PDFs führen zu falschen Antworten — auch bei einem technisch einwandfrei konfigurierten System.
Phase 2 — Chunking, Embedding & Indexierung: Die bereinigten Dokumente werden in semantische Abschnitte (typischerweise 300–800 Token) unterteilt und als Vektoren in einer Vektordatenbank gespeichert. Hier entscheiden sich maßgeblich Antwortgenauigkeit und Abrufgeschwindigkeit. Chunk-Größe, Überlappungsstrategie und Embedding-Modell sind die wichtigsten Stellschrauben.
Phase 3 — Pilot & Evaluierung: Ein kontrollierter Pilot mit einer definierten Nutzergruppe (z. B. Kundenservice oder HR) liefert echte Qualitätsdaten. Goldstandard-Fragen mit bekannten Antworten erlauben eine objektive Messung der Präzision. Erst wenn Precision und Recall stabil über einem festgelegten Schwellenwert liegen, wird die nächste Phase eingeleitet.
Phase 4 — Rollout, Zugriffskontrolle & Betrieb: Nicht jeder Mitarbeiter sollte auf alle Dokumente zugreifen dürfen. Personalakten, Gehaltsstrukturen, strategische Planungsdokumente — ein produktions-reifes RAG-System muss Zugriffsrechte aus dem bestehenden IAM-System (Active Directory, Entra ID) erben und durchsetzen. Dokumente, auf die ein Nutzer kein Leserecht hat, dürfen weder abgerufen noch als Kontext an das Sprachmodell übergeben werden.
DSGVO-Konformität: Was beim RAG-System wirklich zählt
Die DSGVO-Frage ist beim RAG-System eine andere als beim direkten API-Einsatz von ChatGPT oder Copilot. Im RAG-Szenario verlassen Ihre Quelldokumente das Unternehmen nicht — sie werden lokal indexiert und gespeichert. Nur die jeweilige Nutzeranfrage und die abgerufenen Passagen werden an das Sprachmodell übergeben. Wenn dieses Modell on-premise oder in einem zertifizierten EU-Rechenzentrum läuft, ist der datenschutzrechtliche Handlungsbedarf minimal.
Kritischer ist die Frage, welche personenbezogenen Daten in den Quelldokumenten stecken. E-Mail-Archive, Kundenkorrespondenz und HR-Dokumente sollten entweder pseudonymisiert, zugriffsbeschränkt oder gänzlich aus dem RAG-Index ausgeschlossen werden. Eine sorgfältige Dokumentenklassifizierung in Phase 1 ist daher keine technische Fleißarbeit — sie ist die datenschutzrechtliche Grundlage des gesamten Systems.
Wer ein Open-Source-Modell wie Llama oder Mistral selbst hostet, hat die volle Datensouveränität. Wer einen Cloud-Provider nutzt, sollte auf Verarbeitung ausschließlich in der EU, einen unterschriebenen Auftragsverarbeitungsvertrag (AVV) und die Abschaltung von Training auf Kundendaten achten. Anbieter wie Microsoft Azure OpenAI, AWS Bedrock oder Google Vertex AI bieten diese Optionen explizit an — aber nur, wenn sie aktiv konfiguriert werden.